










El último documento de Flare research presenta un nuevo enfoque de la inteligencia artificial (IA), en el que la combinación de IA con blockchain conduce a una IA más segura y precisa.
El aprendizaje por consenso (AC) hace posible la IA colaborativa en un amplio abanico de aplicaciones, permitiendo el desarrollo de modelos de IA más precisos y sólidos. El CL es especialmente adecuado para la integración de la IA en sectores sensibles a los datos, como la sanidad o las finanzas, mejorando así los procesos de toma de decisiones y aumentando el rendimiento y la eficiencia operativos generales, lo que a su vez puede traducirse en un menor coste de los servicios para el consumidor final. Esto puede traducirse en una mejora significativa de los resultados de la atención al paciente, un análisis financiero más preciso o una mejor detección del fraude, entre otras ventajas. A diferencia de la mayoría de las implementaciones existentes de IA y blockchain, que permiten el acceso al aprendizaje automático (ML) centralizado a través de la blockchain, CL aprovecha la blockchain para crear modelos de IA descentralizados.
Motivaciones
En los últimos años se ha hecho cada vez más hincapié en los entornos distribuidos, en los que los datos y los recursos informáticos están repartidos entre múltiples dispositivos. Este cambio viene impulsado por los requisitos de los modelos de fundamentos modernos, como los grandes modelos lingüísticos y los modelos de visión por ordenador, que exigen cantidades sustanciales de datos para su procesamiento. En este entorno distribuido pero aún centralizado, la descentralización surge como una necesidad fundamental, impulsada por varias motivaciones clave.
Los métodos centralizados presentan riesgos inherentes al depender de una única parte de confianza, lo que confina su uso principalmente a entornos de una sola empresa y limita su adopción más amplia. Además, estas arquitecturas no sólo aumentan la vulnerabilidad frente a posibles ataques o fallos del sistema, sino que también suscitan preocupación por la privacidad y la seguridad de los datos. Por el contrario, los métodos descentralizados presentan una clara ventaja: permiten a los usuarios desarrollar modelos locales personalizados, adaptados a sus necesidades y preferencias específicas, mientras que los enfoques centralizados suelen carecer de la flexibilidad necesaria para tal personalización. En medio de estas limitaciones, el aprendizaje por consenso emerge como una solución de ML descentralizada que ofrece mayor resistencia, privacidad y adaptabilidad, al tiempo que mitiga los riesgos inherentes asociados a la centralización.
Ventajas del aprendizaje por consenso
Los protocolos de consenso son esenciales para la seguridad de los libros de contabilidad descentralizados y protegen las redes blockchain de ataques maliciosos. Aprovechar los mecanismos de consenso para la IA tiene muchas ventajas, entre las que destacamos las siguientes:
- Mayor rendimiento. Los métodos de CL se benefician de los datos de cada uno de sus contribuyentes, lo que reduce el sesgo y mejora la capacidad de los modelos para generalizar en datos no vistos. CL también puede conducir a una IA más precisa en comparación con los métodos centralizados, principalmente debido a la capacidad de blockchain para incentivar la colaboración, lo que lleva a una mayor competencia en la combinación de diversas ideas de diversos modelos. Esto se consigue mediante múltiples agregaciones locales, en las que cada participante evalúa las predicciones de los modelos vecinos y las integra para mejorar la precisión. Este es uno de los primeros casos en los que la IA puede obtener ventajas significativas de la integración de la cadena de bloques.
- Seguridad. En presencia de agentes malintencionados que intenten introducir objetivos ocultos, la integridad de los modelos de CL permanece intacta gracias a las características de seguridad integradas en los mecanismos de consenso. Esto garantiza que los sistemas de IA se abstengan de generar predicciones dañinas deliberadas o imprecisiones involuntarias, ambas características propias de la IA maliciosa. Por consiguiente, CL responde a una de las principales preocupaciones de la comunidad de la IA: protegerla de la explotación con fines perjudiciales. Al defender la integridad del proceso de aprendizaje colaborativo, CL infunde mayor confianza en los sistemas de IA, allanando el camino para su despliegue responsable y ético.
- Privacidad de los datos. En CL, ni los datos subyacentes de los participantes en la red ni sus modelos individuales se comparten en ningún momento. De hecho, no hay ataques maliciosos en la red capaces de comprometer la confidencialidad de los datos, ya que éstos permanecen almacenados localmente. Preservar la privacidad no sólo fomenta la colaboración, sino que también preserva la competitividad. En este sentido, CL permite la monetización de los datos a través de la IA, especialmente en el caso de datos sensibles o comerciales como los de la sanidad, superando los retos anteriores encontrados en entornos centralizados.
- Descentralización total. Los datos y los recursos computacionales se distribuyen a través de una red de participantes, que se comunican sin depender de un único servidor central. La necesidad de descentralización se hace patente en las aplicaciones modernas de ML debido a la demanda de grandes cantidades de recursos y a la creciente complejidad de los modelos de ML. El ML descentralizado surge como una solución más adecuada para preservar la privacidad de los datos y garantizar la seguridad.
- Eficiencia. El proceso de aprendizaje tiene una baja latencia y requiere mucho menos tiempo de cálculo, energía y recursos que otros métodos de ML descentralizados de última generación. Esto hace que CL sea especialmente adecuado para aplicaciones en tiempo real, en las que la rapidez en la toma de decisiones y la utilización eficiente de los recursos son primordiales.
Cómo funciona
El aprendizaje por consenso mejora los métodos de ensemble mediante una fase de comunicación, en la que los participantes comparten sus resultados (del modelo) hasta llegar a un acuerdo. El aprendizaje por consenso es un proceso en dos fases que puede aplicarse del siguiente modo:
- Fase de aprendizaje individual. Cada participante en la red desarrolla su propio modelo, basándose en sus datos privados y en otros datos públicos disponibles. Esto puede ir desde la construcción de un modelo desde cero hasta el uso de grandes modelos preentrenados y su ajuste a sus necesidades. Lo más importante es que nunca se pedirá a los participantes que compartan información confidencial sobre sus datos o su modelo. Una vez completado el entrenamiento, los participantes prepararán sus predicciones iniciales para un conjunto de datos de prueba, que puede ser un conjunto de datos revelado a través de un contrato inteligente o, alternativamente, los participantes pueden proponer nuevos puntos de datos de prueba a través de un mecanismo Proof-of-Stake, por ejemplo.
- Fase de comunicación. Los participantes transmiten sus predicciones iniciales dentro de la red según un protocolo de consenso/gossip. Durante estos intercambios, los participantes actualizan continuamente sus predicciones para reflejar las valoraciones de los demás participantes de la red, así como la confianza en sus propias predicciones. Además, un participante puede controlar la calidad de las predicciones recibidas del resto de la red y utilizarla para mejorar la toma de decisiones. Al final de esta fase, los participantes llegan a un acuerdo ("consenso") sobre la decisión que se considera óptima teniendo en cuenta la información disponible en la red. Esta fase se repite para cualquier nueva entrada de datos.
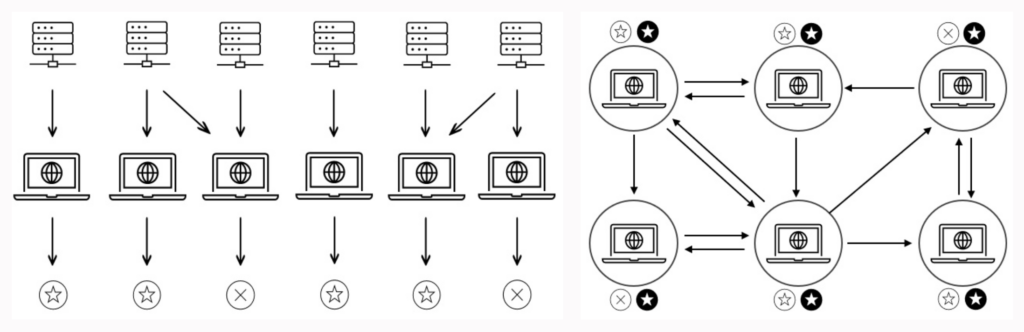
Leyenda de la figura: Un ejemplo de cómo funciona CL para una tarea de clasificación binaria. (a) En la primera fase, los participantes desarrollan sus propios modelos, basados en sus propios datos y, posiblemente, en otros datos compartidos voluntariamente por otros participantes. Al final de esta fase, cada modelo determina una predicción inicial (representada por los círculos huecos) para cualquier entrada del conjunto de datos de prueba. (b) En la fase de comunicación, los participantes intercambian y actualizan sus predicciones iniciales, llegando finalmente a un consenso sobre un único resultado (representado por los círculos rellenos). Esta fase se repite para cualquier nueva entrada de datos.
En sentido estricto, el algoritmo descrito anteriormente se refiere a un escenario de ML supervisado; en concreto, se trata de un escenario en el que los conjuntos de datos de entrenamiento ya están etiquetados y en el que el algoritmo realiza predicciones para las etiquetas de los nuevos datos de prueba no vistos. Sin embargo, la CL también puede adaptarse a problemas de ML autosupervisado o no supervisado, en los que los participantes sólo tienen acceso a datos parcial o totalmente sin etiquetar. Los objetivos de estos métodos son ligeramente diferentes, lo que exige que los participantes empleen técnicas distintas durante la fase de aprendizaje individual. No obstante, la fase de comunicación se desarrollaría de forma similar a la descripción anterior.
Cómo se distingue el aprendizaje por consenso
La idea que subyace a CL es la de combinar eficazmente conocimientos (en forma de modelos de IA) procedentes de múltiples fuentes sin compartir ninguna información sensible o valiosa ni la propiedad intelectual. Este enfoque está diseñado para proteger la información confidencial, al tiempo que garantiza la resistencia frente a posibles riesgos planteados por entidades maliciosas. CL se basa en el paradigma del aprendizaje por conjuntos (ensemble learning), de gran éxito, que proporciona técnicas potentes para fusionar múltiples modelos en uno solo. Los métodos de ensemble se basan en el principio de la "sabiduría de las multitudes", que aprovecha el conocimiento colectivo de una multitud para superar el de cualquier miembro individual.
En los últimos años han surgido varias implementaciones de blockchain de servicios de IA, que muestran enfoques innovadores para integrar la IA con redes descentralizadas. Por ejemplo, Bittensor facilita las inferencias de IA (salida de modelos) dentro de sus subredes de dominios específicos, ponderando las predicciones de los "mineros" mediante un mecanismo teórico de juegos. FLock.io ofrece una plataforma para el aprendizaje federado (un tipo diferente de aprendizaje distribuido), aunque con un agregador centralizado, que utiliza la blockchain para validar las actualizaciones de los modelos y recompensar a los participantes. Otro ejemplo es Ritual, que opera efectivamente un mercado para modelos de ML a través de su protocolo Infernet, donde las solicitudes para ejecutar un modelo específico se envían al propietario del modelo.
CL se distingue por su método de agregación distinto, en el que las predicciones de los modelos individuales pasan a través de un protocolo de cotilleo seguro con el fin de llegar a un acuerdo. Como tal, CL aprovecha blockchain para crear modelos de IA descentralizados, mientras que las implementaciones existentes permiten el acceso a ML centralizado a través de blockchain. El objetivo es permitir una IA más precisa y segura a través de la colaboración, al tiempo que se permite a las entidades que poseen datos privados, a menudo sensibles, unirse al sistema, garantizando la confidencialidad de sus datos.
En resumen
El aprendizaje por consenso presenta una oportunidad innovadora para aplicar el aprendizaje automático directamente en libros de contabilidad descentralizados como las cadenas de bloques. Con esta iniciativa, asistimos a la aparición de un enfoque novedoso en el que la tecnología blockchain puede mejorar fundamentalmente las herramientas de IA existentes. Esto abre posibilidades apasionantes para la innovación y la colaboración segura en sectores tradicionalmente sensibles a los datos, como la sanidad, sentando las bases para la adopción de técnicas de ML colaborativo. Además, la resistencia de los métodos de CL frente a factores maliciosos fomenta una mayor confianza en los sistemas de IA, fortificando su fiabilidad e integridad.
